


Aurich Lawson | Getty Photos
With most pc packages—even complicated ones—you may meticulously hint by means of the code and reminiscence utilization to determine why that program generates any particular habits or output. That is usually not true within the discipline of generative AI, the place the non-interpretable neural networks underlying these fashions make it onerous for even specialists to determine exactly why they usually confabulate info, as an illustration.
Now, new analysis from Anthropic affords a brand new window into what is going on on contained in the Claude LLM’s “black field.” The corporate’s new paper on “Extracting Interpretable Options from Claude 3 Sonnet” describes a strong new technique for not less than partially explaining simply how the mannequin’s hundreds of thousands of synthetic neurons fireplace to create surprisingly lifelike responses to normal queries.
Opening the hood
When analyzing an LLM, it is trivial to see which particular synthetic neurons are activated in response to any explicit question. However LLMs do not merely retailer completely different phrases or ideas in a single neuron. As a substitute, as Anthropic’s researchers clarify, “it seems that every idea is represented throughout many neurons, and every neuron is concerned in representing many ideas.”
To type out this one-to-many and many-to-one mess, a system of sparse auto-encoders and sophisticated math can be utilized to run a “dictionary studying” algorithm throughout the mannequin. This course of highlights which teams of neurons are usually activated most persistently for the precise phrases that seem throughout varied textual content prompts.

These multidimensional neuron patterns are then sorted into so-called “options” related to sure phrases or ideas. These options can embody something from easy correct nouns just like the Golden Gate Bridge to extra summary ideas like programming errors or the addition perform in pc code and sometimes symbolize the identical idea throughout a number of languages and communication modes (e.g., textual content and pictures).
An October 2023 Anthropic examine confirmed how this fundamental course of can work on extraordinarily small, one-layer toy fashions. The corporate’s new paper scales that up immensely, figuring out tens of hundreds of thousands of options which are energetic in its mid-sized Claude 3.0 Sonnet mannequin. The ensuing function map—which you’ll partially discover—creates “a tough conceptual map of [Claude’s] inner states midway by means of its computation” and exhibits “a depth, breadth, and abstraction reflecting Sonnet’s superior capabilities,” the researchers write. On the identical time, although, the researchers warn that that is “an incomplete description of the mannequin’s inner representations” that is probably “orders of magnitude” smaller than a whole mapping of Claude 3.
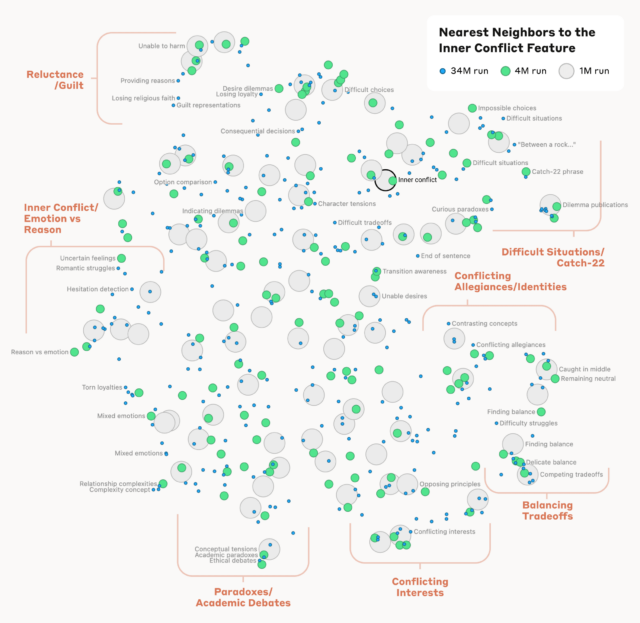
Even at a floor stage, shopping by means of this function map helps present how Claude hyperlinks sure key phrases, phrases, and ideas into one thing approximating information. A function labeled as “Capitals,” as an illustration, tends to activate strongly on the phrases “capital metropolis” but additionally particular metropolis names like Riga, Berlin, Azerbaijan, Islamabad, and Montpelier, Vermont, to call just some.
The examine additionally calculates a mathematical measure of “distance” between completely different options primarily based on their neuronal similarity. The ensuing “function neighborhoods” discovered by this course of are “usually organized in geometrically associated clusters that share a semantic relationship,” the researchers write, exhibiting that “the interior group of ideas within the AI mannequin corresponds, not less than considerably, to our human notions of similarity.” The Golden Gate Bridge function, as an illustration, is comparatively “shut” to options describing “Alcatraz Island, Ghirardelli Sq., the Golden State Warriors, California Governor Gavin Newsom, the 1906 earthquake, and the San Francisco-set Alfred Hitchcock movie Vertigo.”
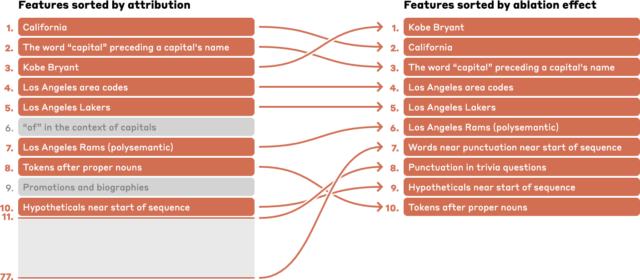
Figuring out particular LLM options can even assist researchers map out the chain of inference that the mannequin makes use of to reply complicated questions. A immediate about “The capital of the state the place Kobe Bryant performed basketball,” as an illustration, exhibits exercise in a sequence of options associated to “Kobe Bryant,” “Los Angeles Lakers,” “California,” “Capitals,” and “Sacramento,” to call just a few calculated to have the best impact on the outcomes.




